Designing Data Intensive Applications Notes: Ch.2 Data Models and Query Languages
aboelkassem | November 02, 2023

Continuing our series for “Designing Data-Intensive Applications” book.
In this article, we will walkthrough the second chapter of this book Chapter.2 Data Models and Query Languages.
Table of Content (TOC)
Data models are perhaps the most important part of developing software, because they have such a profound effect on the way we think about the problems we’re solving.
Relational Model vs Document Model
The best-known data model today is probably that of SQL, based on the relational model: data is organized into relations (called tables in SQL), where each relation is an unordered collection of tuples (rows in SQL).
by the mid-1980s, relational database management systems (RDBMSes) and SQL had become the tools of choice for most people who needed to store and query data with some kind of regular structure.
Relational model today’s use case for transaction processing (entering sales or banking transactions, airline reservations, stock-keeping in warehouses) and batch processing (customer invoicing, payroll, reporting).
The goal of the relational model was to hide that implementation detail behind a cleaner interface.
In the 2010s, NoSQL is the latest attempt to overthrow the relational model’s dominance. NoSQL name refer to 2009 twitter hashtag for new open source, non relational database meaning “Not Only SQL”.
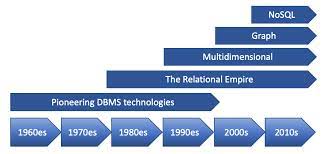
NoSQL databases have been adopted quickly and easily because:
- It provided a better scaling mechanism, including very high write throughput than relational databases
- It was free and open source
- It supported few specific query operations better than relational databases
- It provided more dynamic and expressive data model than relational databases
Relational databases will continue to be used alongside a broad variety of non-relational datastores (Polyglot Persistence).
Many applications today is done in object-oriented programming languages. An translation layer is required between the objects in application code and the database model of tables, rows, and columns (SQL). Object-relational mapping (ORM) frameworks like ActiveRecord, EntityFramework, and Hibernate reduce the amount of boilerplate code required for this translation layer, but they can’t completely hide the differences between the two models.
The following image illustrate an example of resume (a LinkedIn profile) expressed in a relational schema.
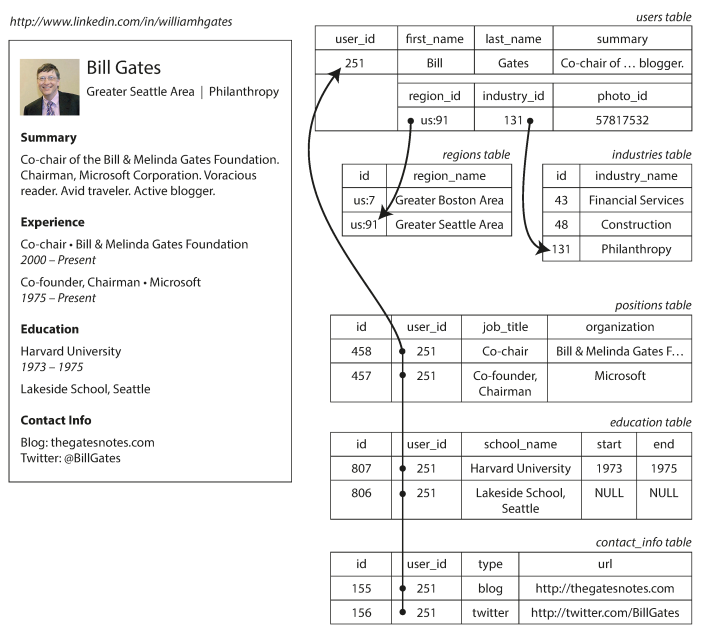
Relational databases deal with the one-to-many relationship in one of three ways:
- The common normalized way is to put the many values in a separate table, with foreign key reference to the one (like the above image)
- Later versions of SQL allowed multi-valued data be stored in a single row, with support for querying inside them (XML or JSON datatypes).
- The least favorable option is to store them as encoded JSON or XML, and let the application do the internal query.
JSON representation has better locality than the multi-table schema (Instead of doing multiple joins or queries in tables, in JSON all the relevant information is in one place, and one query is sufficient)
Document-oriented databases on the other hand supports one-to-many relationship natively, and provides better locality for the data object, thanks to the self-contained nature of JSON.
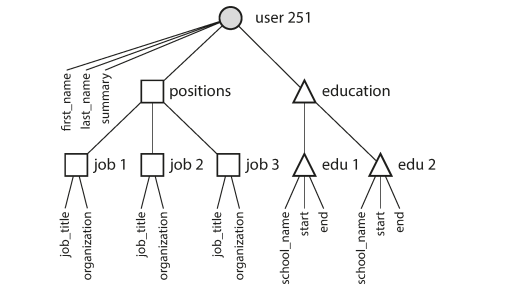
Many-to-One and Many-to-Many Relationships
Removing such duplication is the key idea behind normalization in databases.
Relational databases deal with many-to-one relationship by referring to rows in tables by ID, as joins are easy. However, Document databases doesn’t nicely support many-to-one relationships. Instead, the application code would need to go through the overhead of simulating the join itself, which can cache it all in memory if it’s small and slow-changing.
Document database worked well for one-to-many relationships, but it made many-to-many relationships difficult, and it didn’t support joins. Developers had to decide whether to duplicate (denormalize) data or to manually resolve references from one record to another.
In a relational database, the query optimizer automatically decides which parts of the query to execute in which order, and which indexes to use. The relational model thus made it much easier to add new features to applications.
When comparing document model to relational model, arguments in favor of document model are schema flexibility, better performance, and more-matching data structure with the application, while Relational model provides better support for joins, and many-to-one and many-to-many relationships.
Which data model leads to simpler application code?
- If the data in your application has a document-like structure (i.e., a tree of one-to-many relationships, where typically the entire tree is loaded at once or no relationships between records) then it’s probably a good idea to use a document model.
- If your application does use many-to-many relationships and joins, the relational model is more suitable.
Document databases are not schemaless, but rather have schema on read (the structure of the data is implicit, and only interpreted when the data is read) similar to dynamic (runtime) in oppose to relational model’s schema on write (where the schema is explicit and the database ensures all written data conforms to it). It is not enforced by the database, but more easier to change and modify similar to static (compile-time).
Example of storing each user’s full name in one field, and you instead want to store the first name and last name separately.
- In a document database, you would just start writing new documents with the new fields and have code in the application that handles the case when old documents are read. For example:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}- On the other hand, in a “statically typed” database schema, you would typically perform a migration along the lines of:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQLThe schema-on-read approach is advantageous if the items in the collection don’t all
have the same structure for some reason (i.e., the data is heterogeneous)—for example, because:
- There are many different types of objects, and it is not practical to put each type of object in its own table.
- The structure of the data is determined by external systems over which you have no control and which may change at any time.
In situations like these, a schema may hurt more than it helps, and schemaless documents can be a much more natural data model. But in cases where all records are expected to have the same structure, schemas are a useful mechanism for documenting and enforcing that structure.
For document databases to benefit from locality (retrieve all document data and no need to joins lookups), documents have to be relatively small in size. It is generally recommended that you keep documents fairly small and avoid writes that increase the size of a document
Google’s Spanner database offers the same locality properties in a relational data model, by allowing the schema to declare that a table’s rows should be nested within a parent table. Oracle allows the same, using a feature called multi-table index cluster tables. The column-family concept in the Bigtable data model (used in Cassandra and HBase) has a similar purpose of managing locality.
It seems that relational and document databases are becoming more similar overtime. PostgreSQL and MySQL become support JSON documents. RethinkDB supports relational-like joins, and some MongoDB drivers automatically resolve database references (effectively performing a client-side join, although this is likely to be slower than a join performed in the database).
A hybrid of relational and document models might be the future of databases, as they are becoming more similar over time. If a database is able to handle document-like data and also perform relational queries on it, applications can use the combination of features that best fits their needs.
Query Languages for Data
SQL is a declarative query language which is attractive because it is typically more concise and easier to work with than an imperative API. it also hides implementation details of the database engine, which makes it possible for the database system to introduce performance improvements and optimizations. Like
SELECT * FROM animals WHERE family = 'Sharks';Also, declarative code is easier to parallelize across multiple machines.
An example for declarative and imperative on web.
The following HTML and CSS code to highlight the sharks as selected in the html structure
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li>
<p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>
// CSS
li.selected > p {
background-color: blue;
}If you want to use imperative approach, in javascript using the core Document Object Model (DOM) API.
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}Not only is it much longer and harder to understand than the CSS equivalents. Similarly, in databases, declarative query languages like SQL turned out to be much better than imperative query APIs.
MapReduce Querying
MapReduce is a programming model for processing large amounts of data in bulk across many machines, popularized by Google. A limited form of MapReduce is supported by some NoSQL datastores, including MongoDB and CouchDB, as a mechanism for performing read-only queries across many documents. MapReduce is neither a declarative query language nor a fully imperative query API, but somewhere in between.
Example of the same query in PostgreSQL and MongoDB for a marine and you add an observation record every time you see animals in the ocean, and want to generate a report with how many sharks per months.
In PostgreSQL
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;In MongoDB
// if the collections are
{
observationTimestamp: Date.parse("Mon, 25 Dec 1995 12:34:56 GMT"),
family: "Sharks",
species: "Carcharodon carcharias",
numAnimals: 3
},
{
observationTimestamp: Date.parse("Tue, 12 Dec 1995 16:17:18 GMT"),
family: "Sharks",
species: "Carcharias taurus",
numAnimals: 4
}
db.observations.mapReduce(
function map() { // called every document that matchs the query
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals); // emits a key and value like ("2013-12", list<animals>)
},
function reduce(key, values) { // grouped by key like => "1995-12", [3, 4]
return Array.sum(values); // add up the number of observations
},
{
query: { family: "Sharks" }, // filter by only sharks
out: "monthlySharkReport" // write the output to monthlySharkReport collection
}
);MapReduce is a fairly low-level programming model for distributed execution on a cluster of machines. Higher-level query languages like SQL can be implemented as a pipeline of MapReduce operations.
MongoDB 2.2 added support for a declarative query language called the aggregation pipeline. The aggregation pipeline language is similar in expressiveness to a subset of SQL.
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}}
]);Graph-Like Data Models
Graph data model is usually the most suitable model for data with a lot of many-to-many relationships. A graph consists of two kinds of objects: vertices (also known as nodes or entities) and edges (also known as relationships or arcs).
Example of Graph data:
- Social graphs: Vertices are people, and edges indicate which people know each other.
- The web graph: Vertices are web pages, and edges indicate HTML links to other pages.
- Road or rail networks: Vertices are junctions, and edges represent the roads between them.
There are many well-known algorithms which can operate on graphs (like shortest path between two points or PageRank in web graph to determine popularity of web page in search results).
Facebook maintains a single graph with many different types of vertices and edges: vertices represent people, locations, events, checkins, and comments made by users; edges indicate which people are friends with each other, which checkin happened in which location, who commented on which post, who attended which event, and so on.
There are two kinds of graph models: property graph model (implemented by Neo4j, Titan, and InfiniteGraph), and the triple-store model (implemented by Datomic, AllegroGraph, and others). Also there some good declarative query languages such as Cypher for efficient querying or SPARQL or Datalog.
Property Graphs
each vertex consists of:
- A unique identifier
- A set of outgoing edges
- A set of incoming edges
- A collection of properties (key-value pairs)
Each edge consists of:
- A unique identifier
- The tail vertex
- The head vertex
- A label to describe the kind of relationship between the two vertices
- A collection of properties (key-value pairs)
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);The Cypher Query Language
Cypher is a declarative query language for property graphs, created for the Neo4j graph database.
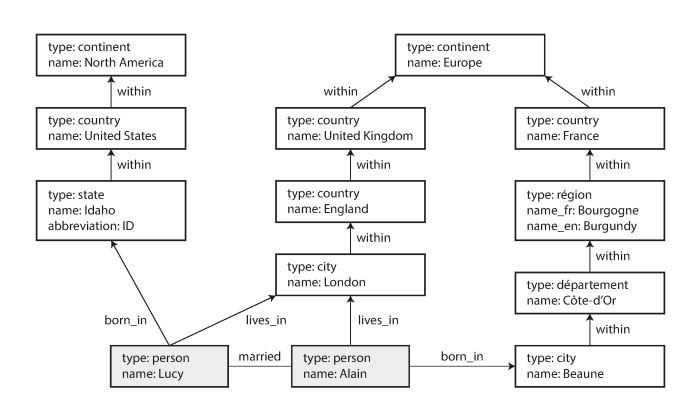
Subset of the data of above image represented as a cypher query
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)Each vertex is given a symbolic name like USA or Idaho, and other parts of the query can use those names to create edges between the vertices, using an arrow notation: (Idaho) -[:WITHIN]-> (USA) creates an edge labeled WITHIN, with Idaho as the tail node and USA as the head node.
Cypher query to find people who emigrated from the US to Europe
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.nameFind any vertex (call it person) that meets both of the following conditions:
- person has an outgoing BORN_IN edge to some vertex. From that vertex, you can follow a chain of outgoing WITHIN edges until eventually you reach a vertex of type Location, whose name property is equal to “United States”.
- That same person vertex also has an outgoing LIVES_IN edge. Following that edge, and then a chain of outgoing WITHIN edges, you eventually reach a vertex of type Location, whose name property is equal to “Europe”
The same query as above, expressed in SQL using recursive common table expressions.
WITH RECURSIVE
-- in_usa is the set of vertex IDs of all locations within the United States
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name' = 'United States'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe is the set of vertex IDs of all locations within Europe
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name' = 'Europe'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
),
-- born_in_usa is the set of vertex IDs of all people born in the US
born_in_usa(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
),
-- lives_in_europe is the set of vertex IDs of all people living in Europe
lives_in_europe(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
)
SELECT vertices.properties->>'name'
FROM vertices
-- join to find those people who were both born in the US *and* live in Europe
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;Triple-Stores and SPARQL
Triple-store model is mostly equivalent to the property graph model, using different words to describe the same ideas. In a triple-store, all information is stored in the form of very simple three-part statements: (subject, predicate, object). For example, in the triple (Jim, likes, bananas), Jim is the subject, likes is the predicate (verb), and bananas is the object.
The following example shows the same data as in above example, written as triples in a format called Turtle, a subset of Notation3.
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".The SPARQL query language for triple-stores.